[CNN] R-CNN의 업그레이드, Fast R-CNN
저번에 CNN에 대한 이론적 내용을 소개하면서 R-CNN까지 설명했습니다.
하지만 R-CNN은 추출한 영역들을 모두 CNN 모델에 보내서 분류를 하기때문에 속도가 느리다는 단점이 있었고 이 점을 보완하고자 하여 만들어진것이 Fast R-CNN이라고 할 수 있습니다.
참고 논문 : arxiv.org/pdf/1504.08083.pdf
R-CNN의 한계
논문에 따르면 3가지 단점이 있다고 한다.
1. Traning is a multil-stage pipline (학습에 많은 스테이지 과정이 필요)
R-CNN은 학습을 하기까지 로그 손실함수(log loss)를 사용하여 합성곱층(ConvNet)을 조정한다. SVM은 분류기(Object Detectors)로서 사용되고 softmax를 통해 미세조정(fine-tuning)되며 이렇게 3단계를 거져 박스(Boungding box)를 그리는 학습을 하게 된다.
쉽게 말하면 학습을 할때 여러단계를 거쳐야 되기때문에 한번에 학습할 수 없다는 말이다.
2. Training is expensive in space and time (학습의 비용이 너무 비싸다, 공간과 시간에 대해서)
VGG16의 경우 5K개의 이미지를 가진 VOC07 데이터셋을 2.5 GPU/일(해석이 정확하지 않음)이 걸리며 저장하는 용량도 수백 기가바이트(GB)가 필요하다.
쉽게 말하면 오래걸리고 저장공간이 많이 필요하다, 즉 비싸다.
3. Object detection is slow (객체 탐지가 느리다.)
VGG16의 경우 이미지당 그래픽카드(GPU)를 사용했을때 47초가 소요된다.
한마디로 너무 느리다.
위와 같은 단점들이 있기때문에 단점을 해결한 Fast R-CNN이 등장하게 된 것이다.
Fast R-CNN의 등장
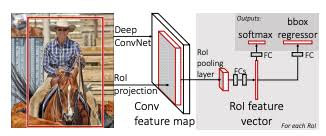
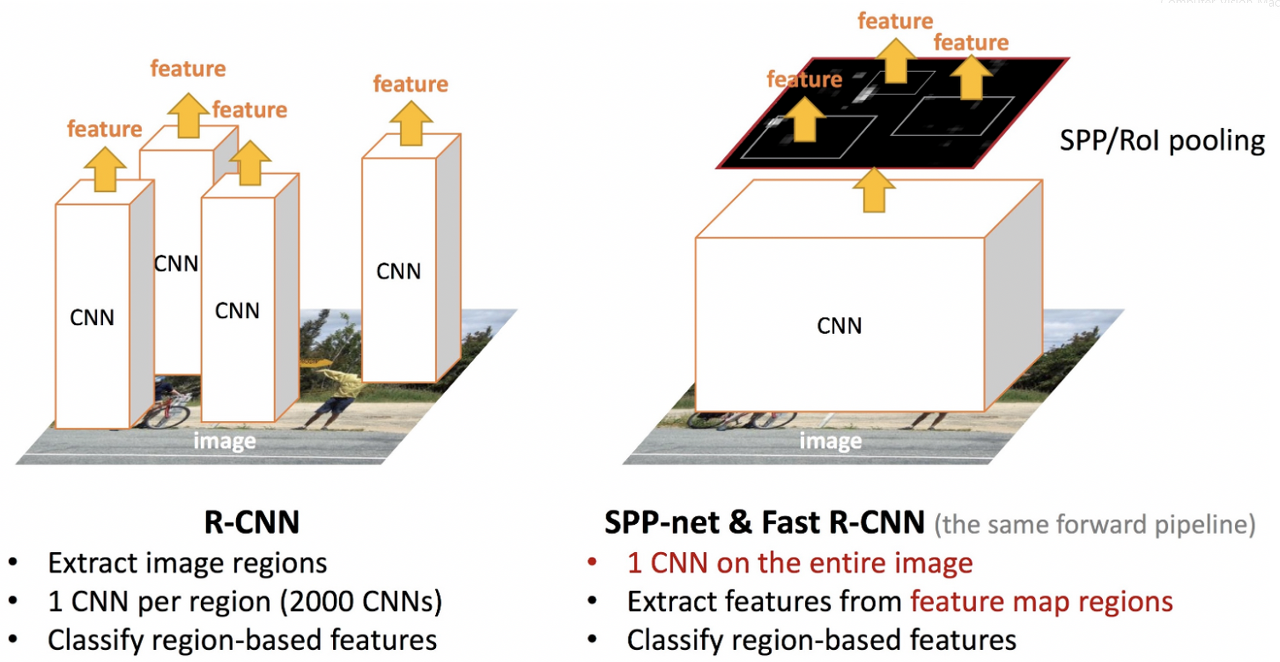
Fast R-CNN은 R-CNN의 단점을 두 가지를 사용하여 해결하고자 하였다.
1. RoI Pooling Layer (이미지에서 추출한 영역을 풀링 연산하는 층) 추가
2. 따로 진행되던 특징추출(Extract Feature) 분류(Classification), 박스 그리기(Bounding Box Regression)를 하나의 모델에서 학습
이 중 RoI Pooling이 핵심인데 기존의 R-CNN에서는 합성곱층(Conv Layer)의 결과물이 완전연결층(Fully Connected Layer)의 입력으로 들어가야 했기때문에 추출한 RoI를 조정해서 사이즈를 맞췄다. 하지만 이 과정때문에 비용이 비싸지는 것이었는데 R-CNN의 작동 순서와 원리를 약간 바꿔 해결하게 된다.
일단 R-CNN과 같이 박스가 있을만한 곳(Region Proposal)을 뽑아낸 뒤, 그 영역을 사이즈 조절하지 않고 전체 이미지를 한 개로 CNN 모델에 넣은 다음 거기서 나온 특징맵(Feature Map)에서 RoI를 추출하는 방식으로 바꾸었다. 그렇기 때문에 입력되는 이미지의 수가 2000장에서 1장으로 줄어들게 되었고 비용도 줄어들게 되었다.
순서를 정리하면 다음과 같다.
1) 선택적 탐색(Selective Search)로 RoI 영역을 뽑는다.
2) CNN 모델이 이미지를 따로가 아닌 전체를 집어넣어 특징맵(Feature Map)을 뽑아낸다.
3) 뽑아놓았던 RoI 영역에 특징맵(Feature Map)을 넣은 뒤 RoI Pooling을 진행한다.
4) 완전연결층(Fully Connected Layer)를 거쳐 분류(Classification), 박스그리기(Bounding Box Regression)를 진행
R-CNN과 거의 비슷하지만 Pooling Layer가 들어가며 기존의 단점을 해결할 수 있었다고 한다.
(조금 더 깊이있는 내용은 추후 추가)
실시간 객체 탐지의 시작
Fast R-CNN의 개념이 등장하며 실시간 객체 탐지(Real Time Object Detection)의 시대가 시작되게 되었다. 단순한 이미지 분류기에서 Regions의 개념을 붙이며 객체 탐지의 길로, R-CNN의 단점을 해결하여 0.7fps와 같이 처참한 성능을 보여주던 모습에서 실시간으로 움직이는 영상에 객체 탐지가 가능해지게 된 Fast R-CNN까지 계속해서 발전해 나가고 있다. 하지만 Fast R-CNN 또한 이미지당 2초정도가 소요되며 20배 이상 줄어들긴 했지만 실시간 영상에 사용하기에는 역부족인 성능이다. 여기서 연구를 멈추었을리가 없다. 여기에 더욱 빨라진 Faster R-CNN이 등장하게 된 것이다.
Faster R-CNN 또한 Fast R-CNN의 단점을 분석한 뒤 해결방법에 대해 서술하고자 하는데 해당 내용은 다음 편에 진행하도록 하겠다.
함께 읽으면 좋은 내용
[공부하는 중~~/인공지능] - [CNN] CNN 기본 지식
[공부하는 중~~/인공지능] - [CNN] CNN, R-CNN? 쉽게 알아보자