안녕하세요 대추입니다.
최근에 RetinaNet에 대해 개념정리하는 글을 작성하고 있었는데 설명하기 위해서는 CNN에 대한 지식이 있어야 하는데 저번에 정리한 CNN에 대한 글은 너무 기능에 집중된 글인 것 같아 이론적인 부분을 더 추가적으로 포스팅한 뒤에 여러 분류, 객체 탐지 알고리즘에 대한 글을 작성하고자 합니다.
[CNN] CNN 기본 지식
CNN 간단한 프로세스 설명 1. Layer들을 쌓는다. (Conv, Pooling 레이어를 반복해서 쌓거나 Conv, Conv, Pooling과 같은 식으로 쌓는 방식으로 쌓아 모델을 만든다.) (VGG16의 경우 16이 이런 레이어가 16개 있다.
daechu.tistory.com
해당 글은 arxiv.org/pdf/1311.2524.pdf 에 있는 CNN에 객체 탐지(Object Detection)를 적용시킨 R-CNN 논문을 바탕으로 쓰고자 합니다.
CNN이 뭔데?
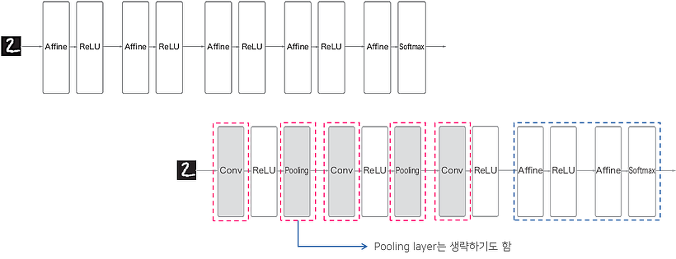
CNN은 Convolutional Neural Networks의 약자이며 인간의 뇌를 따라한 신경망으로 수많은 계층과 뉴런, 연산으로 이루어져 있다. 기존의 ANN이 인접하는 계층들의 모든 뉴런들이 연결되어 있는 완전연결 방식(Full connected)으로 이루어져 있는 것과 다르게 Conv layer라고 불리는 합성곱층과 Pooling layer라고 불리는 풀링층이 더해진 것이다. ANN의 경우 데이터의 형상이 무시된다는 문제점이 있었는데 그 문제를 해결하기위해 합성곱 연산과 풀링층을 더한 것이다. 데이터의 형상이 무시되는게 큰 문제가 될까? 문제가 된다.
완전연결층(Full connected layer)은 세로, 가로, 채널로 되어있는 3차원 데이터를 입력받기위해 1차원의 데이터로 펼쳐야 하며 그 과정에서 3차원 데이터만이 가진 정보들이 사라져 의도한대로 학습이 되지 않을수도 있다. 반면 합성곱층은 합성곱을 통해 3차원의 데이터를 연산할때 변환없이 그대로 입력받고 출력 또한 3차원의 데이터로 출력하게 되어 3차원 데이터만이 가진 정보를 가지고 완전연결층(Full connected layer)보다 데이터에 대한 학습을 잘 할 가능성이 높아지게 된다. 이를 한 줄로 정리하자면 합성곱층(Convolutional layer)은 완전연결층(Fully connected layer)보다 형상을 가진 데이터를 학습하는데 좋다라고 정리할 수 있다.
이런 이점을 가진 CNN을 어디에 써먹을까? 바로 이미지에 대한 응용이다. 이미지에는 형상이 있고, 이 형상을 CNN에 넣어 연산을 한다면 이미지를 분류한다던가 이미지에서 객체를 탐지하는 것을 기존의 ANN보다 훨씬 잘할 것이다. 그래서 이미지 분류대회의 순위표를 보면 기존의 모델들을 재치고 CNN이 차지하고있고 요즘에는 이미지에 관련된 것은 대부분 CNN을 사용한다.
(그래서 ANN은 또 뭔데? 포스팅을 하다보니 공부하는 것과 반대로 하향식으로 하게되는데 조만간 다루겠다.)
CNN이 왜 등장했고 뭔지 알았는데 R-CNN은 또 뭐야?
어렵게 생각할 필요가 없다. R-CNN은 앞에 R이 붙었고 R이 뭔지만 알면 끝이다.
처음에 말한 논문이 CNN에 R을 붙여 그에 대한 분석을 한 논문이다. R은 Regions로 CNN이 이미지의 분류에 객체 탐지(Object Detection)가 추가된 것이다. 단순한 이미지의 분류를 넘어서 객체의 탐지까지, 무궁무진한 응용이 가능해지게 된 것이다.

논문에서는 R-CNN의 과정을 4단계로 설명하는데
1. 이미지를 입력한다.
2. (~2000여개)의 영역을 추출한다. (이때 사용하는 알고리즘은 선택적 탐색(Selective Search))
3. 2번에서 추출한 영역들을 CNN 모델에 넣어 계산한다.
4. 3번의 결과물을 분류한다.
우리가 알아들을 수 있는 말은 1, 3, 4번이다. CNN 모델에 이미지를 입력하고 계산하여 이미지가 뭔지 분류해주는 것이고 여기에 R의 Regions의 기능을 2번 과정이 해주는 것이다. 이미지 한 장을 분류하는 것에서 이미지에서 객체가 있을만한 곳을 찾아 추출한 뒤 추출한 이미지들을 각각 분류하는 것으로 바뀌었을뿐 큰 틀은 똑같다고 볼 수 있다.
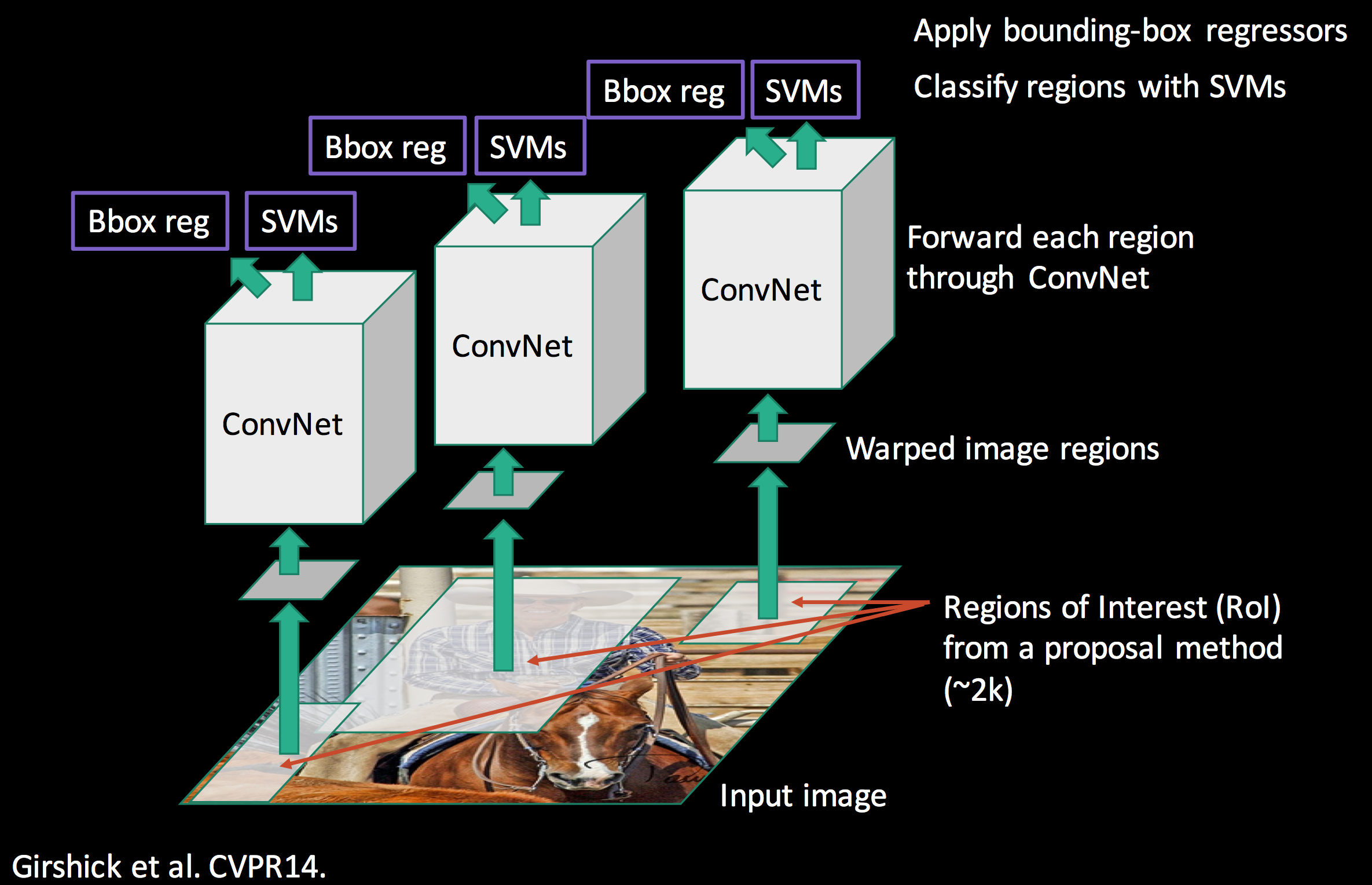
논문팀에서는 위의 과정을 진행하기위해 3가지의 모듈로 구성된 시스템을 사용했다고 한다.
1. 객체가 있을만한 곳을 찾는 모듈 (Regioal Proposal)
2. 특징을 찾아내는 모듈 (Feature Extraction, CNN)
3. 분류를 하기위한 모듈 (선형 지도학습 모델, SVM)
하나씩 간단하게 소개하자면
1. 객체가 있을만한 곳을 찾는 모듈 (Regioal Proposal)

선택적 탐색(Selective Search)을 사용해 영역을 찾는데 선택적 탐색이란 이미지의 색을 수학 연산을 통해 유사도를 계산하고 가장 유사도가 높은 영역을 선택하여 병합하고 선택된 영역과 병합되지 못했지만 연관이된 다른 영역을 제거하고 다시 유사도를 계산하고 유사도 집합에 포함, 계산, 병합을 반복하는 것이다. 상당히 복잡해 보이는데 아래의 과정을 반복하는 것이다.
1) 가장 유사도가 높은 영역을 선택
2) 선택된 영역을 병합
3) 선택된 영역과 병합되지 못했지만 연관이된 다른 영역을 제거
4) 병합된 영역과 나머지 영역들의 유사도를 다시 계산
5) 유사도 집합에 병합된 영역을 추가
6) 하나의 영역이 됐나? (yes : end, no : continue)
2, 3. 특징을 찾아내는 모듈 (Feature Extraction, CNN), 분류를 하기위한 모듈 (선형 지도학습 모델, SVM)

사진에서 네모 박스로 Bbox reg, SVMs라고 적혀있는데 추출된 특징(Feature)을 연산하는 것이다. CNN 모델에서 나온 결과물을 SVM을 사용해 분류(Classification)를 진행한다. 여기서 CNN 모델로 이미지의 특징을 찾아내고 SVM은 분류기(Classifier)로서의 역할을 한다는 정도만 알아두면 된다.
이런 과정을 통해 객체 탐지(Object Detection)를 진행하고 좋은 성능을 보인다고 한다. 자세한 연산의 과정이나 평가 기준같은 것은 이해가 잘 되지않고 너무 어려워서 궁금하다면 논문이나 다른 포스트들을 읽어보는 것을 추천한다.
최대한 쉽게 풀어쓴다고 적었지만 처음보는 용어, 한글인데 한글이 아닌거 같은 말들이 있다. 하지만 글을 읽는 다면 CNN이 무엇인지 왜 ANN에 합성곱층과 풀링층을 추가했는지, 이미지 응용에 적합한 이유가 무엇인지, R-CNN이 뭔지에 대해 맥락을 이해할 수 있을 것이라 생각한다.
모자란 부분, 틀린 부분은 수시로 수정, 추가할 예정이다.
'공부하는 중~~ > 인공지능' 카테고리의 다른 글
| [CNN] R-CNN의 업그레이드, Fast R-CNN (0) | 2020.10.29 |
|---|---|
| [인공지능] 인공지능 용어 정리 (0) | 2020.10.26 |
| [RetinaNet] RetinaNet 개념 정리 (추가중) (0) | 2020.10.23 |
| [Colab] AI 공부하는데 그래픽카드가 없어? 걱정하지마 colab이 있잖아!! (0) | 2020.10.16 |
| [VGGNet] VGGNet 개념 정리 (2) | 2020.10.14 |




댓글